With Twitter being a mess at the moment, I decided to try out Mastodon1 as an alternative. Mastodon is a federated social media platform, built on top of a protocol called ActivityPub2. It can be self-hosted, letting you own your data, and I wanted to do so using Nomad3 as a cluster orchestrator. This post shows how I did it, and will hopefully inspire you to give Mastodon a try if you haven’t already! You can find me on the fediverse at @lopcode@mastodon.social 🐘.
# Getting started
The first thing to note is that I’m writing this up as inspiration, not as a step-by-step guide. It’s prove that it works, and offer an alternative to more complex setups that use Kubernetes (which Mastodon have a first-party Helm Chart4 for). Your mileage may vary - use your best judgement! If you know of improvements, feel free to send me a message at the link above.
This post is meant to be read with the repository that I’ve open-sourced, containing the actual Nomad task definitions and scripts discussed below: https://github.com/lopcode/nomad-mastodon
With that out of the way, let’s start with some goals and assumptions. I wanted to:
- Self-host a Mastodon server, such that I could own my social media presence
- Host the server infrastructure on AWS
- Use Cloudflare in some capacity for caching
- Use Nomad to do cluster orchestration and keep jobs running
- Use Ansible and Terraform to manage the basic infrastructure (not in scope for this post)
- Not spend more than around $50 a month doing so
It’s worth noting that my budget balances my financial situation, the tooling I’m already familiar with, and performance of the system. You can definitely do things cheaper if budget is a primary concern, for example by using cheaper cloud providers like DigitalOcean. If you’d rather have someone else host Mastodon for you, cheaper services like masto.host exist too.
# Infrastructure
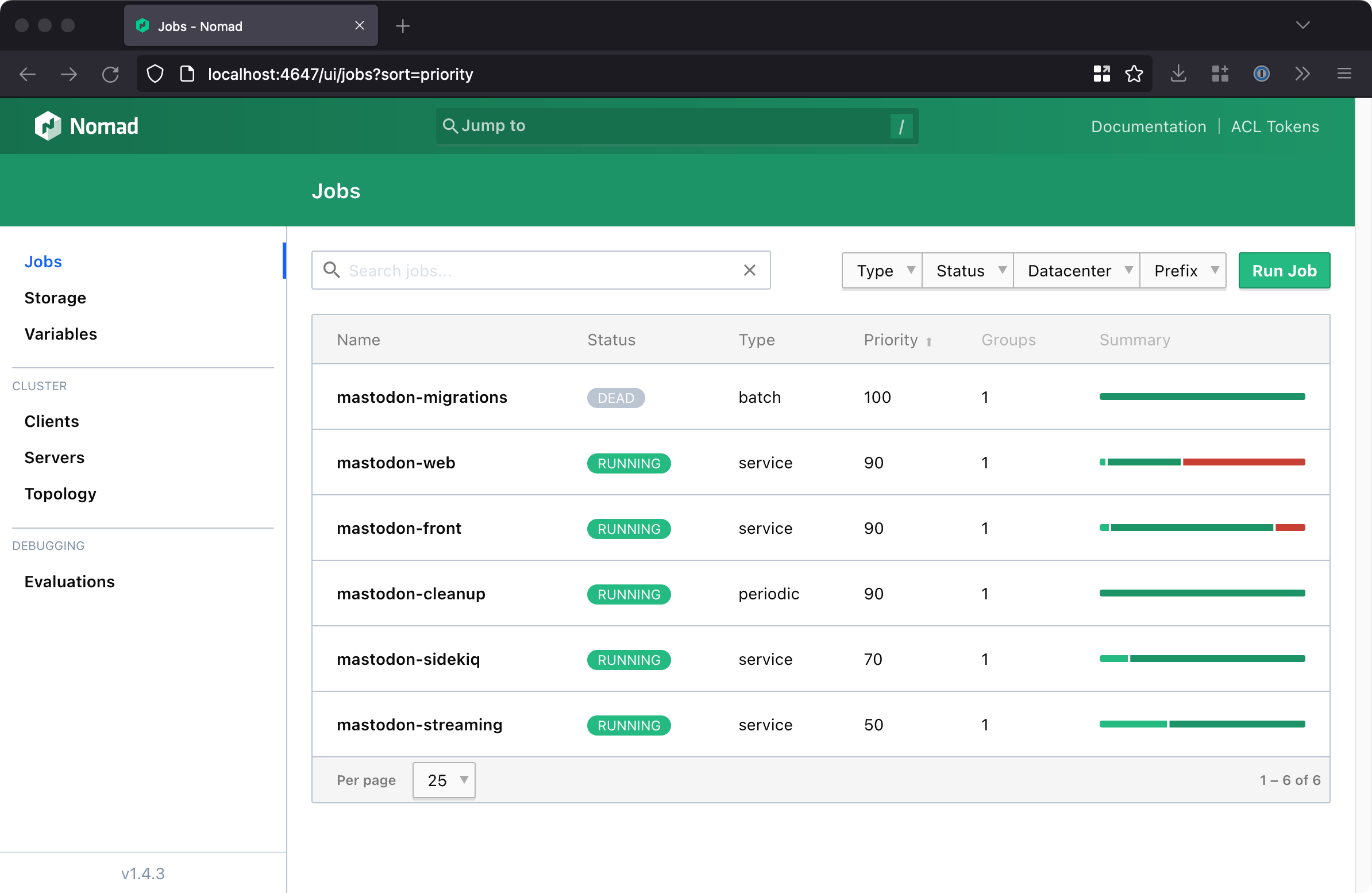
Mastodon itself is comprised of a number of systems:
- The main web server (Ruby on Rails)
- An event/message processor (Sidekiq, Ruby on Rails)
- A front proxy to route web requests (nginx)
- A streaming server, for real-time updates (Node)
- A persistent database (Postgres)
- A cache for “temporary” data (Redis)
On top of this, there are some other necessities to run it, and keep the system healthy after the initial setup:
- Persistent storage, for user-generated content (S3-compatible)
- A way of doing frequent cleanup (removing old media files, accounts, etc)
- A way to run SQL migrations, for both the message processor and web server
- A way to run
tootctl- the administrative CLI for Mastodon5
As mentioned, I’m using Terraform and Ansible to manage my infrastructure. These tools have a lot of benefits, including making the act of setting up networking and servers repeatable, and documenting what exists in your cloud account. I strongly encourage you to use these tools (or alternatives) to manage your infrastructure, if you’re not already doing so.
# Main components
There were some obvious choices on AWS for the main components - EC2 to run a server, RDS for a persistent database, and Elasticache for a Redis-compatible temporary data store. In researching S3 I also discovered that Cloudflare offer an S3-compatible service imaginatively named “R2”. It integrates nicely with their edge-caching service, and offers competitive pricing and performance, so I decided to give that a try as well.
There’s not too much to say about the Nomad jobs themselves - each primary job maps in to a Nomad job definition file (suffixed .nomad - for example, mastodon-web for the main web server). Mastodon have a first-party docker-compose.yml file6, to start up docker containers automatically, and you can use that to understand how to start each of the components. Secrets are passed in as Nomad variables, mapping to environment variables in the specific task. A future improvement noted below is to figure out a way to share these environment variables across job definitions, but for now, they’re copy/pasted between jobs via a template file.
# Other components
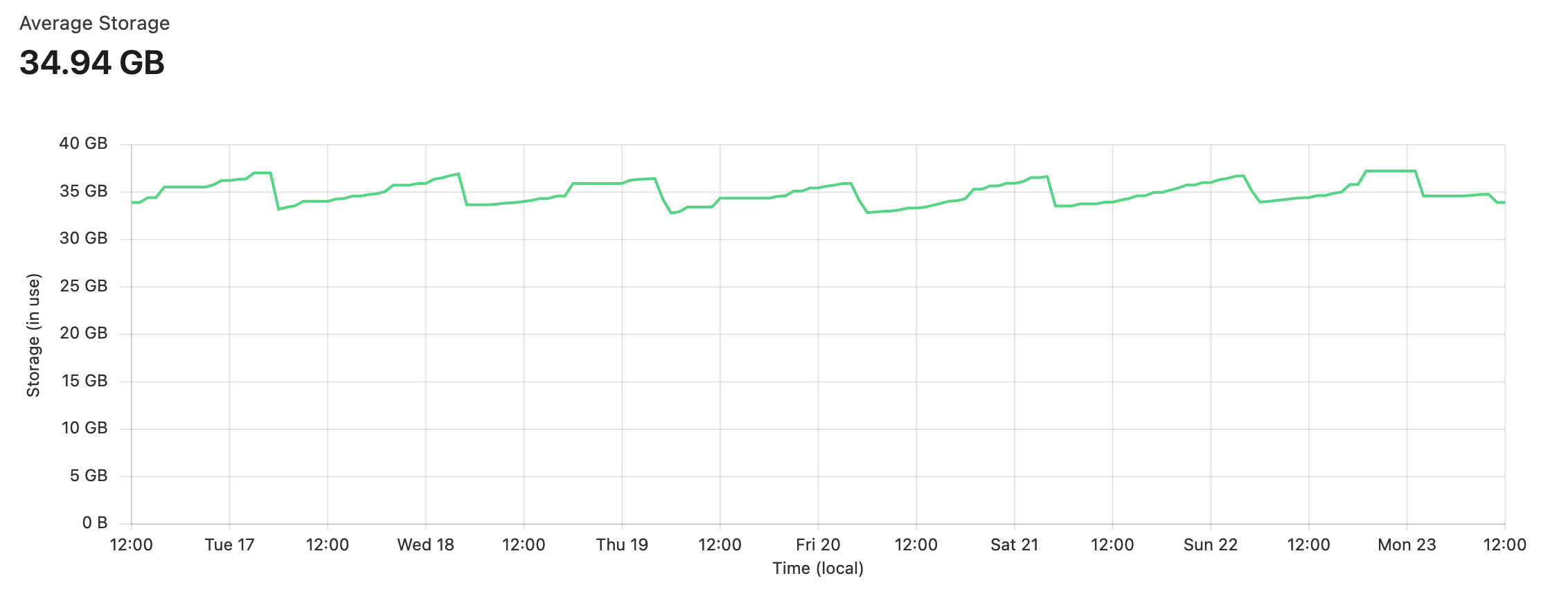
Nomad offers “periodic” tasks with a cron-like interface, to let you run tasks on a frequent schedule, which is perfect for the “frequent cleanup” requirement. The cleanup job starts tootctl with some specific commands to remove media after a certain number of days, which I configured to 30 to start with. Media storage is something you should be aware of with Mastodon - it stores a “local” copy of media relevant for the users of your server. It can end up being quite a lot, so a good strategy to reduce your bill is to store discovered media for less time. The only downside being said media will have to be refetched when required again. Below is a graph of the storage usage for bunny.cloud - you can see media being cleaned up every day at 4am as it expires.
For running SQL migrations, I could see two choices:
- Pick a job to run migrations in, as a “startup task” - for example, every time the message processor job starts
- Add a “batch” job to run migrations as part of a deployment
I chose to use a batch job, because I wanted to control when I ran migrations, and decouple that process from running other critical components. This is because there are multiple jobs that require the migrations - at the very least, the main web server, and the message processor. Having a separate job means migrations can run before either of those jobs start. In practice I think the message processor would also be a decent choice.
tootctl
Another aspect of administrating a Mastodon server, is interacting with tootctl to do manual tasks. The tricky bit with a cluster orchestration system is “where do you run the command”? I think it’s overkill to spin up a dedicated entire job to run a single administrative command every now and then, so we have to pick a running job to run the command inside.
Nomad offers really handy CLI to inspect running jobs, and execute commands inside their tasks (called allocs). I’ve included a script, tootctl.sh, to let you run tootctl commands inside the message processing task on-demand. Usage is exactly the same as the original command, just through the script:
🥕 carrot 🗂 bunny-cloud-infra/infra/cluster 🐙 main $ ./tootctl.sh version
Discovering alloc of "mastodon-sidekiq" to run tootctl in...
Found alloc with ID: ef0fd901-d598-9fe6-b2c2-3c577c0aee2e
Executing: "tootctl version"
4.0.2
# Future improvements
I’m a fan of shipping things and iterating, so there are a few obvious improvements that I plan on making:
- Figure out a way to more easily share environment variables across jobs - it’s annoying having to copy a template to several files when they change, even if it’s rare
- Migrate away from using “host networking” in the container definitions. Although the message processor task could reasonably autoscale in response to demand, using host networking means web server ports are statically assigned, making it impossible to run more than one replica
- Investigate Nomad’s recently shipped “autoscaling” features, to spin up more message processing tasks in periods of high CPU load (or even detecting a message backlog)
# Conclusion
Hopefully this inspired you to give self-hosting Mastodon a go, if you’re so inclined. I’ve also proven that you don’t need a complicated Kubernetes setup to get a lot cluster orchestration goodness. In total this setup costs around $45 a month, which is happily within my budget. That’s the cost for a single person on my server, so if there were more people who contributed to the running costs, it would rapidly get cheaper.
I also hope that more people give Mastodon a go - I’m really enjoying it so far, and feel that it’s a much healthier form of social media for me. I’ve been struggling with Twitter feeling toxic for a while, and having a space that I can share things to without being sold adverts, or served divisive content to push platform metrics, is something I value greatly.
Is there another aspect of this setup you’d like to know about in more detail? Feel free to ask over on the fediverse, at @lopcode@mastodon.social!
# Footnotes
-
Mastodon website - https://joinmastodon.org/ ↩
-
ActivityPub specification - https://www.w3.org/TR/activitypub/ ↩
-
Nomad cluster orchestrator - https://www.nomadproject.io/ ↩
-
Mastodon Helm Chart - https://github.com/mastodon/chart ↩
-
Mastodon
docker-compose.yml- https://github.com/mastodon/mastodon/blob/main/docker-compose.yml ↩
Posts in this series: