This post is an end-to-end description of how I built and shipped a new feature for this website - the live-updating sponsor list on the support page ✨. I wanted a way to recognise sponsors on the website, and I really wanted it to be live, so that someone could sponsor and almost immediately see their bunny show up on the page.
I’ll run through the entire process of building the feature - from gathering requirements, to planning, and implementing a solution. Although I won’t include all the code, I will include snippets where something is particularly interesting.
# Requirements
As with any non-trivial technical project, I started by making a new project page on Notion1, and drafting a list of requirements. I almost always start projects by listing requirements, and planning - I find it focuses the implementation, and helps prevent scope creep. With that in mind, this is what I wrote down:
- There should be a bunny loaf for every Patreon sponsor, shown on the support page
- The buns should be displayed in a responsive grid and look nice on mobile too
- The component should include a visual display of the current sponsorship goal
- The list should update as quickly as is reasonably possible - ideally live
- Sponsor privacy should be respected - if a person hides their sponsorships, they should show up as “Anonymous”
- If fancier browser features aren’t available, the component should fall back to using basic REST calls
# Planning
With a list of requirements done, the next thing I needed to do was check what the capabilities of the Patreon API2 were. I knew that there were definitely lists of sponsors available, but had no idea about how performant the API was, or whether it could support the fancier features like live updating, or sponsor privacy. I quickly spotted a message on their developer portal saying that, whilst endpoints would continue to function, they’re focusing on “the core product” - suggesting they don’t believe the API is part of that core. But it does clearly say that endpoints would continue to function, so I wasn’t too worried about the API going away.3
Browsing around the documentation suggested that there indeed were endpoints that could return sponsor data. Newer endpoints (version 2) use a standard called JSON API4 which I’m not a fan of - I find it over-complicates endpoints, adding quite a bit of structural overhead, and requires extra libraries to parse out information in the format that the API designer intended. It’s not a deal-breaker though, and just means the integration will be a little harder.
The main endpoint that I was interested in is the “campaign members” endpoint: GET /api/oauth2/v2/campaigns/{campaign_id}/members. I generated myself an API token on the developer portal, and used HTTPie5 to make some requests locally to validate the data, and “kick the tyres”, so to speak. Here’s an example of the kind of requests I was making in my terminal (noting that 725055 is the “campaign ID” for my Patreon page):
🥕 carrot 🗂 ~/git/carrot.blog 🐙 main $
http https://www.patreon.com/api/oauth2/v2/campaigns/725055/members\?include=currently_entitled_tiers,user\&fields\[member\]=full_name,patron_status\&fields\[tier\]=title,amount_cents,created_at,description\&fields\[user\]=vanity,full_name,hide_pledges Authorization:"Bearer <snip>"
I should also note that there is pagination on all the new endpoints, but that I’m nowhere near the page limit (which I think is 20 items), so I haven’t implemented support for it yet. In practice this means that if I got an influx of supporters, they might not all show up until I implemented this API feature, but I’m confident it would take about an hour to ship. A nice problem to have, for sure.
One of my requirements was having a visual indication of the current sponsor goal (like 3 / 20). The V2 API does not include a way of fetching “sponsor count” goals, only monetisation goals, so I fell back to the V1 API for this particular piece of information. That bit is included in the V1 campaigns endpoint: GET /api/oauth2/api/current_user/campaigns?include=patron_goals
Finally, I noticed that the API also supports webhooks6, which was great to see. That meant it was likely possible to avoid repeatedly polling the Patreon API, which can be slow at times, and I wasn’t sure about hitting rate limits (as there aren’t any hard guidelines noted on the developer docs). Instead, I could register a webhook and refresh the list of patrons, when notified that there was a change. The developer portal also supports sending test webhook messages which makes iterating on the feature much easier.
Now I knew my way around the API, I could start building, which would involve infrastructure, backend, and frontend work.
# Building
With the planning and API investigation done, I could start building the actual service 🚀.
# Infrastructure
This website is almost completely static, compiled using Jekyll, hosted on GitHub Pages7, and fronted using Cloudflare8, so the first thing to set up was infrastructure - I needed a place to run the API service. I have quite a bit of prior experience using DigitalOcean9, and the $6 “droplet” instances offer a really cheap, robust way to test out ideas, so I went with that platform.
Automating infrastructure, and deploying services in a repeatable way, are hard requirements for my projects nowadays. I have quite a number of things on the go, so it’s impossible to keep every project’s implementation details in my head. Coming back to a project in 6 months, and trying to unpick what you did, is a rubbish experience (and one I’m sure other software engineers can relate to). I went with what I knew - terraform10 to define the infrastructure, and ansible11 to provision it. Both tools have good API integrations with DigitalOcean, which makes defining and provisioning infrastructure pretty straightforward.
Defining a droplet in terraform, with monitoring enabled, IPv6, and a floating IP, looks like this (noting that some of the backing information like a VPC for networking, or SSH key, is omitted):
resource "digitalocean_droplet" "carrot_blog_1" {
name = "carrot-blog-1"
image = "docker-20-04"
region = "lon1"
size = "s-1vcpu-1gb-intel"
vpc_uuid = digitalocean_vpc.carrot_blog.id
tags = ["carrot_blog"]
monitoring = true
ipv6 = true
ssh_keys = [digitalocean_ssh_key.carrot.fingerprint]
user_data = <<EOF
#! /bin/bash
sudo hostnamectl set-hostname carrot-blog-1
EOF
}
resource "digitalocean_floating_ip" "carrot_blog_1" {
droplet_id = digitalocean_droplet.carrot_blog_1.id
region = digitalocean_droplet.carrot_blog_1.region
}
DigitalOcean helpfully provide a “Docker” base image (the docker-20-04 bit above), so there isn’t actually that much to provision with ansible - just the basics like making sure the firewall is configured correctly, and changing Docker DNS settings. The only thing worth noting is that it’s best to use ansible’s “dynamic inventory” feature, where it queries the DigitalOcean API to figure out what the IP addresses of your droplets are. Otherwise, you’d have to change your “inventory file” every time the IP changed, which is a bit of a faff.
There’s a community ansible plugin called community.digitalocean.digitalocean which you can use for the dynamic inventory. I made a file called digital_ocean.yaml, containing:
plugin: community.digitalocean.digitalocean
api_token: '{{ lookup("pipe", "./get-do-token.sh") }}'
attributes:
- id
- name
- memory
- vcpus
- disk
- size
- image
- networks
- volume_ids
- tags
- region
keyed_groups:
- key: do_region.slug
prefix: 'region'
separator: '_'
- key: do_tags | lower
prefix: ''
separator: ''
compose:
ansible_host: do_networks.v4 | selectattr('type','eq','public')
| map(attribute='ip_address') | first
class: do_size.description | lower
distro: do_image.distribution | lower
filters:
- '"carrot_blog" in do_tags'
This file tells the plugin to filter by the carrot_blog tag, and maps the DigitalOcean API response in to attributes that can be used when running ansible playbooks. It references another script, get-do-token.sh, to get a valid API token from my local keychain:
#!/usr/bin/env bash
set -eou pipefail
security find-generic-password -a ${USER} -s CARROT_BLOG_DO_API_TOKEN -w
Running the playbook then looks like this (where infra.yaml is the ansible playbook I’ve defined to provision the server):
#!/usr/bin/env bash
set -eou pipefail
CARROT_BLOG_DO_API_TOKEN="$(./get-do-token.sh)"
CARROT_BLOG_AGENT_IDENTITY="~/.ssh/id_rsa_carrot_blog"
ANSIBLE_HOST_KEY_CHECKING=False
DO_API_TOKEN="${CARROT_BLOG_DO_API_TOKEN}" ansible-playbook -u root \
--private-key "${CARROT_BLOG_AGENT_IDENTITY}" \
--inventory-file=digital_ocean.yaml \
-e 'ansible_python_interpreter=/usr/bin/python3' \
infra.yaml "$@"
# Backend service
With a place to put the API server, I could start building the backend service that would make calls to the Patreon API, and cache the results. As before, I went with what I know, and chose Ktor12 for the framework. It’s a Kotlin web framework built by JetBrains (the same people who created Kotlin itself) and I’ve enjoyed using it for other projects in the past.
It’s good to build features incrementally instead of all at once, so I started with a very basic endpoint that used some hand-crafted “fetchers” to piece together bits of the Patreon API, in to a list of privacy-aware sponsors. As I mentioned before, the Patreon API uses the “JSON API” standard, and I didn’t want to complicate the project by depending on many third party libraries, so I decided to just piece these together in the fetchers themselves using the Kotlin standard library. It was a good excuse to try Kotlin’s kotlinx.serialization13 library, which can generate serialization code without using Java reflection. Instead, you annotate data classes in your code, and it uses an annotation processor to create the appropriate serialization logic during compilation. I’ve put an entire “fetcher” up in a GitHub Gist if you’d like to get a feeling for what those classes do14.
During the previous stage of planning I noted that sometimes the Patreon API could be quite slow - taking many seconds to return a list of sponsors. I knew that I would need to cache the results for a certain amount of time, so that my own API could be fast. The actual caching logic can be a bit complicated, to avoid the “thundering herd” problem when lots of clients cause a refresh at the same time, so I hid it behind a ReplayingCache implementation that I won’t go in to in too much detail about here. It both caches results, and handles refreshing the data in a thread-safe way, when a client requests it.
With the cache in place, the endpoint to fetch a list of sponsors looks pretty simple:
package sponsor.api.route
import io.ktor.application.ApplicationCall
import io.ktor.http.HttpStatusCode
import io.ktor.response.respond
import kotlinx.serialization.Serializable
import sponsor.api.cache.ReplayingCache
import sponsor.api.fetcher.SupportersFetching
import sponsor.api.serialization.OffsetDateTimeSerializer
import java.time.OffsetDateTime
import java.time.ZoneOffset
class V1SupportersRoute(
private val supportersCache: ReplayingCache<SupportersFetching.SupportersDTO>
) {
@Serializable
data class SupportersResponse(
val supporters: List<Supporter>,
val goal_count: Int,
val meta: Meta
) {
@Serializable
data class Supporter(
val title: String?
)
@Serializable
data class Meta(
@Serializable(OffsetDateTimeSerializer::class)
val updated_at: OffsetDateTime?
)
}
suspend fun handle(call: ApplicationCall) {
val cachedValue = supportersCache.fetch()
if (cachedValue == null) {
return call.respond(HttpStatusCode.NotFound)
}
val response = SupportersResponse(
supporters = cachedValue.value.supporters,
goal_count = cachedValue.value.goalCount,
meta = SupportersResponse.Meta(
updated_at = cachedValue.updatedAt.atOffset(ZoneOffset.UTC)
)
)
return call.respond(
HttpStatusCode.OK,
response
)
}
}
At this point, almost all of the requirements from above are met 💪. We can hit an API route, which fetches information from Patreon, parses it, and caches the result. The final piece was to make it “as live as reasonably possible”, which I knew would require the use of webhooks and websockets.
A webhook is, in simple terms, when an API provider sends an event to a URL of your choosing, as something happens. You can see why this is helpful for live events - for example, as soon as a new sponsor signs up, Patreon could make a request to our API service saying as much, instead of us asking all the time.
I registered for the members:pledge:create, members:pledge:update, and members:pledge:delete Patreon events using their dashboard. When receiving one of those events, the backend services does a full refresh of the current sponsors, with a cooldown timer to prevent sending lots of requests if a few people sponsor at once. In theory you could use the contents of these events to update the list “piece by piece”, but I’ve often found that to be more hassle than it’s worth - sometimes data in eventually consistent systems doesn’t quite match up at a given point in time, so it’s better to request the entire state to avoid strange inconsistencies.
Finally, I used Ktor’s built-in websocket support to add an endpoint that the frontend could connect to. On connection, the backend would send the full sponsors state, and then monitor the cache to see when anything changed, at which point it sends another full state refresh.
The core of the websocket implementation looks like this (with some functions omitted) - a connection is opened, the full state is sent, and every 10 seconds the state of the cache is checked and sent if there are changes:
suspend fun handle(session: DefaultWebSocketServerSession) {
val connection = trackConnection(session)
var previousValue = supportersCache.fetch()
if (previousValue != null) {
sendFullState(previousValue, connection)
}
while (!session.incoming.isClosedForReceive) {
val newValue = supportersCache.fetch()
if (newValue != null && (previousValue == null || (newValue.value != previousValue.value))) {
previousValue = newValue
sendFullState(newValue, connection)
}
delay(5000L)
}
removeConnection(connection)
}
A trick worth noting here is that the “full state” event sent through the web socket uses exactly the same payload as the REST endpoint, wrapped in a very simple JSON frame:
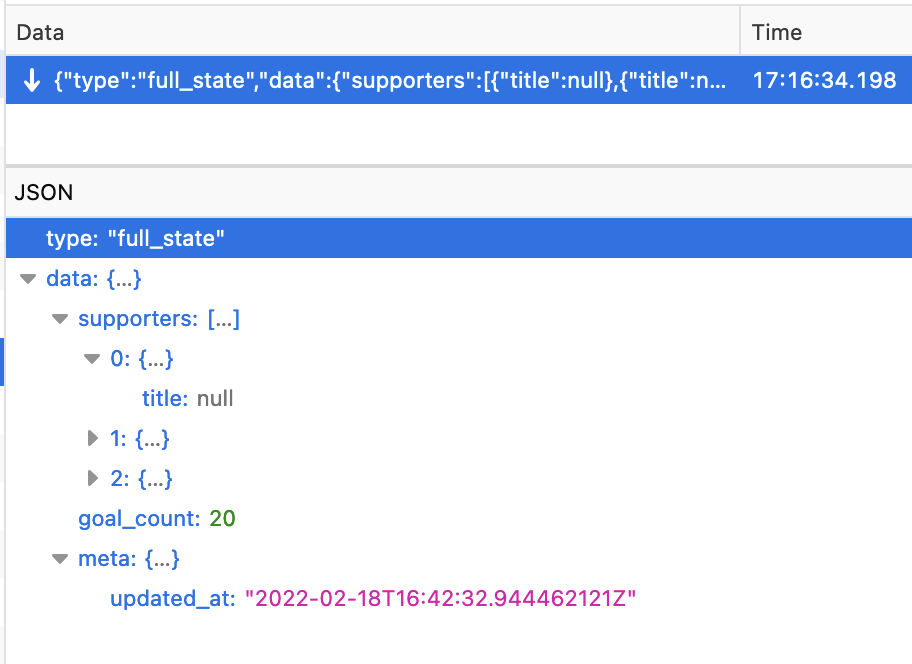
Doing so makes both the backend and frontend implementations simpler, and they both need the same data anyway, so it’s a win-win.
# Frontend
With the backend finished, we can do the final step of integrating it in to the frontend. I have to admit that frontend engineering isn’t my forte, so I chose to keep it as simple as possible - plain Javascript where possible, without any npm modules or build systems, in a single file, so that I can include it in pages in Jekyll as desired.
On page load, the script first checks whether websockets are supported in the browser or not. If not, it uses the REST endpoint described above, and doesn’t attempt to refresh anything live. If websockets are supported, it establishes a connection, listens for full_state events, and attempts to reconnect if the connection is lost (for example, if someone navigates to another browser tab for a while). There’s too much code to include inline, but here the main websocket pieces:
function connectWebsocket() {
const socket = new WebSocket('{{ site.websocket_url }}/v1/supporters/websocket');
socket.addEventListener('message', function (event) {
const message = JSON.parse(event.data);
if (message.type === 'full_state') {
updateSupporters(message.data);
}
});
socket.addEventListener('close', function (event) {
const extraTimeMs = makeRandomInt(0, 4000);
const waitTime = 1000 + extraTimeMs;
console.log("Websocket closed, attempting reconnect in " + waitTime + "ms", event.reason);
setTimeout(function() {
connectWebsocket();
}, waitTime);
});
}
const supportsWebSockets = 'WebSocket' in window || 'MozWebSocket' in window;
if (supportsWebSockets) {
connectWebsocket();
} else {
fetch('{{ site.api_url }}/v1/supporters')
.then(response => response.json())
.then(data => {
updateSupporters(data);
})
.catch((error) => {
for (var div of supportersMessageDivs) {
div.innerHTML = '<p>Failed to load sponsors data from Patreon 💔</p>';
}
});
}
An unexpectedly nice thing I discovered was that, by creating the JavaScript file as a Jekyll include, I could use variables just like you can in mustache templates (in this case, the REST and websocket URLs, {{ site.api_url }} and {{ site.websocket_url }}). Here’s an example of how I include the script on a given page - nice and easy:
## Supporters
These are the kind people who have already sponsored. Hover/click on a loaf to see their name, or add your own. Come back to the page after - it updates live!
{% include patreon_sponsors.html %}
# Conclusion
I’m really pleased with how this feature turned out. I’m especially happy that the list updates live - usually within a few seconds of a patron sponsoring. It was fun to build, and I think it adds a little bit of extra sparkle to the website ✨.
I’ve included the component here, click/tap an empty slot to sponsor and try it out!
I hope this post was helpful, and if you have any questions, I’m happy to answer them on Patreon or Discord!
# Footnotes
-
Notion - https://www.notion.so/ ↩
-
Patreon API documentation - https://docs.patreon.com/#introduction ↩
-
Patreon developer portal - https://www.patreon.com/portal ↩
-
JSON API standard - https://jsonapi.org/ ↩
-
HTTPie - https://httpie.io/ ↩
-
Patreon Webhooks - https://www.patreon.com/portal/registration/register-webhooks ↩
-
GitHub Pages - https://pages.github.com/ ↩
-
Cloudflare - https://www.cloudflare.com/ ↩
-
DigitalOcean (referral link) - https://m.do.co/c/6e8253961242 ↩
-
Terraform - https://www.terraform.io/ ↩
-
Ansible - https://www.ansible.com/ ↩
-
Ktor - https://ktor.io/ ↩
-
kotlinx.serialization - https://github.com/Kotlin/kotlinx.serialization ↩
-
Fetcher example - https://gist.github.com/lopcode/60457a994a3b0b0c7daa55e1f6e3227a ↩